 SQL语言
SQL语言
# SQL语言
# DDL 数据库定义语言
DDL 全称是 Data Definition Language,即数据定义语言,定义语言就是定义关系模式、删除关系、修改关系模式以及创建数据库中的各种对象,比如表、聚簇、索引、视图、函数、存储过程和触发器等等。
数据定义语言是由 SQL 语言集中负责数据结构定义与数据库对象定义的语言,并且由 CREATE、ALTER、DROP 和 TRUNCATE 四个语法组成。
# CREATE 创建数据库
创建一个student表
create table student(
id int identity(1,1) not null,
name varchar(20) null,
course varchar(20) null,
grade numeric null
)
2
3
4
5
6
# ALTER 修改数据库
student 表增加一个年龄字段
alter table student add age int NULL
# DROP 删除结构
删除 student 表
drop table student --删除表的数据和表的结构
student 表删除年龄字段,删除的字段前面需要加 column,不然会报错,而添加字段不需要加 column
alter table student drop Column age
# TRUNCATE 清除数据
只是清空表的数据,但并不删除表的结构,student 表还在只是数据为空
truncate table student
# DML 数据库操纵语言
DML 全程是 Data Manipulation Language,即数据库操纵语言,主要是进行插入元组、删除元组、修改元组的操作。主要由 insert、update、delete 语法组成。
# INSERT 插入数据
插入单条数据:
insert into 表名(字段名1,字段名2,字段名3) values(值1,值2,值3);
批量插入数据:
insert into 表名(字段名1,字段名2,字段名3)
values(值1,值2,值3),
values(值1,值2,值3),
values(值1,值2,值3);
2
3
4
插入默认格式日期
insert into t_user(name,date) values('zqc', '1991-10-19');
插入自定义格式日期
insert into t_user(name,date) values('zqc', str_to_date('01-10-1990', '%d-%m-%y'));
日期格式
年 %Y
月 %m
日 %d
时 %h
分 %i
秒 %s
# UPDATE 修改数据
update 表名 set 字段名1=值1,字段名2=值2 where 条件;
注意:没有条件,所以记录都将被修改
# DELETE 删除数据
delete from 表名 where 条件;
表中数据删除了,数据在硬盘的真实存储空间不释放,支持回滚(rollback),可恢复数据。
注意:没有条件,整张表的数据都被删除。
| 方式 | 说明 |
|---|---|
delete from 表名 where 条件 | 数据被删除,磁盘空间不释放,支持回滚,数据可恢复 |
drop table 表名 | 数据与表结构一起被删除 |
truncate table 表名 | 删除整张表的数据,删除效率高,不支持恢复 |
使用 delete 可能需要一个小时才能删完,truncate 只需要 1 秒
# DCL 数据库控制语言
DCL 全称是 Data Control Language,即数据库控制语言。用来授权或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,能够对数据库进行监视。
比如常见的授权、取消授权、回滚、提交等等操作。
# 创建用户
CREATE USER 用户名@地址 IDENTIFIED BY '密码';
创建一个 testuser 用户,密码 为111111
create user testuser@localhost identified by '111111';
# 用户授权
GRANT 权限1, ..., 权限n ON 数据库.对象 TO 用户名;
将 test 数据库中所有对象(表、视图、存储过程,触发器等。*表示所有对象)的 create, alter, drop, insert, update, delete, select 赋给 testuser 用户
GRANT create,alter,drop,insert,update,delete,select on test.* to testuser@localhost;
# 撤销授权
REVOKE 权限1, ..., 权限n ON 数据库.对象 FROM 用户名;
将 test 数据库中所有对象的 create, alter, drop 权限撤销
REVOKE create,alter,drop on test.* FROM testuser@localhost;
# 查看用户权限
SHOW GRANTS FOR 用户名;
# 删除用户
DROP USER 用户名;
# 修改用户密码
UPDATE USER SET PASSWORD=PASSWORD(‘密码’) WHERE User=’用户名’ and Host=’IP’;
FLUSH PRIVILEGES;
2
# DQL 数据库查询语言
DQL 全称是 Data Query Language,即数据库查询语言,是用来进行数据库中数据的查询的,即最常用的select语句。
执行顺序:from > where > group by > having > select > order by > limit
# 简单查询
查询一个字段
select 字段名 from 表名;
查询两个字段
select 字段名1, 字段名2 from 表名;
查询所有字段
select * from 表名;
效率比较低,可读性较差,因为要把 * 转化为字段
⭐ 给查询列起别名
只是显示,原表名不变
select 字段名1,字段名2 as 新名字2 from 表名;
select 字段名1,字段名2 新名字2 from 表名;
select 字段名1,字段名2 '新名字2' from 表名;
2
3
⭐ 字段可以使用数学表达式
select name,sal*12 as yearsal from emp;
select name,sal*12 as '年薪' from emp;
2
# 条件查询
select 字段名 from 表名 where 条件;
| 表达式 | 说明 |
|---|---|
<> | 不等于 |
between x and y | 在 x 和 y 之间,等同于x <= v and v <= y |
is null | 为空,不能使用=null |
is not null | 不为空 |
or | 或 |
and | 与,优先级大于or |
in | 包含,相当于多个or |
not | 取反 |
like | 模糊查询,支持%或下划线匹配,%匹配任意个字符;_匹配一个字符 |
# 排序
select name,sal from emp order by sal; -- 默认是升序
select name,sal from emp order by sal desc; -- 指定降序
select name,sal from emp order by sal asc; -- 指定升序
select name,sal from emp order by sal asc, name asc; -- 先按照工资升序,工资相同时按照姓名升序
select name,sal from emp order by 2; -- 2表示第二列,第二列是sal
2
3
4
5
# 数据处理函数
⭐ 单行处理函数:一个输入对应一个输出
| 表达式 | 说明 |
|---|---|
lower(str) | 转换小写,select lower(ename) as ename from emp |
upper(str) | 转换大写 |
substr(str,start,length) | 截取字符串,select substr(ename, 1, 1) as ename from emp ,起始下标位从1开始,第二个位长度 |
concat() | 字符串拼接 |
length(str) | 取长度,select length(ename) as enamelength from emp |
trim(str) | 去空格 |
format(num,格式) | 设置千分位,select ename, format(sal, '$999,999') as sal from emp |
round(num,位数) | 四舍五入 |
rand() | 生成随机数,select rand() from emp |
ifnull(val1, val2) | 可以将 null 转换为一个具体的值,select name, (sal + ifnull(comm, 0 )) * 12 as yearsal from emp |
⭐ 多行处理函数:多个输入对应一个输出
| 表达式 | 说明 |
|---|---|
| count | 计数 |
| sum | 求和 |
| avg | 平均值 |
| max | 最大值 |
| min | 最小值 |
注意:
- 使用时必须先分组,没有分组时整张表默认为一组。
- 分组函数自动忽略 null,不需要对 null 进行处理。 count 时会忽略null,sum 时也会忽略 null
- 分组函数不能直接使用在where子句中
count(具体字段):统计该字段下不为 null 元素的总数。
count(*):统计表当中的所有行数。
⭐ 其他
🔶 distinct:把查询结果去除重复记录,原表不会修改
select distinct job from emp;
select distinct job, deptno from emp;
2
🔶limit:将查询结果集的一部分取出来,通常使用在分页查询当中
完整用法: limit startInex, length
缺省用法:limit length ,默认起始下标是0
按照薪资降序,取出排名在前5名的员工:
Select ename, sal from emp order by sal desc limit 5;
注意:limit 在 order by 之后执行
🔶 Union:合并查询结果
-- union的效率要高一些。 分别查询进行拼接
Select ename,job from emp where job = ‘MANAGER’
union
Select ename,job from emp where job = ‘SALESMAN’;
2
3
4
# 分组查询
在实际中,有这样需求,需要先进行分组,然后对一组的数据进行操作,这时候需要分组查询
-- 找出每个工作岗位的工资和
select job, sum(sal) from emp group by job;
-- 找出每个部门的最高工资
select deptno, max(sal) from emp group by deptno;
-- 找出每个部门,不同工作岗位的最高薪资
select deptno, job, max(sal) from emp group by deptno, job;
-- 找出每个部门最高薪资,要求显示最高薪资大于3000
selcet deptno, max(sal) from emp where sal > 3000 group by deptno;
selcet deptno, max(sal) from emp group by deptno having sal > 3000;
- 找出每个部门的平均薪资,要求显示平均薪资大于2500
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2500;
-- 找出每个岗位的平津薪资,要求显示平均薪资大于1500的,除了MANAGER岗位外,并且按照降序排
select job,avg(sal) from emp group by job<>'MANAGER' having avg(sal)>1500 order by avg(sal) desc;
2
3
4
5
6
7
8
9
10
11
12
13
查询顺序:Select…from…where…group by…having…order by…
执行顺序:from、where、group by、having、select、order by
优化策略;where 实在完成不了,再选择 having
# 连接查询
单独查询:从一张表中单独查询
连接查询:跨表查询,多张表联合起来查询数据
分类:SQL92、SQL99
分类:内连接(等值连接、非等值连接、自连接)、外连接(左外连接、右外连接)、全连接
笛卡尔积:当两张表进行连接查询时,没有任何限制时,查询的结果条数是两张表的乘积。
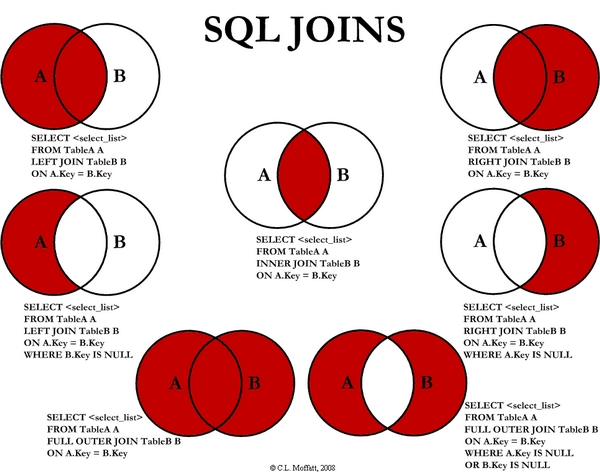
# 内连接
会自动忽略两个表中对应不起来的数据。所以,内连接只显示所有关联的数据,也就是只返回交集。
查询每个员工所在部门名称,显示员工名和部门名:
select ename, dname from emp, dept where emp.deptno = dept.deptno;
匹配次数(遍历) 没减少,只是显示的数目减少了
-- SQL92语法:
Select e.ename, d.dname from emp e, dept d where e.deptno = d.deptno and 其他条件;
-- SQL99语法:
select e.ename, d.dname from emp e inner join dept d on e.deptno = d.deptno where 其他条件;
2
3
4
找出每个员工的薪资等级,要求显示员工名、薪资、薪资等级。
Select e.ename, e.sal, s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal;
查询员工的上级领导,要求显示员工名和对应的领导名。
Select a.ename,b.ename from emp a join emp b on a.mgr = b.empno;
技巧:一张表看成两张表,inner 可以省略
# 外连接
left outer join 等价于 left join:左边是主表,左边表的内容全部显示,右边表显示满足条件的内容。
right outer join 等价于right join:右边是主表,右边表的内容全部显示,左边表显示满足条件的内容。
将dept中的所有情况显示出来,emp 中没有的内容显示 null
Select e.ename, d.ename from emp e right outer join dept d on e.deptno = d.deptno;
查询每个员工的上级领导,要求显示所有员工的名字和领导名。
Select a.ename, b.ename from emp a left join emp b on a.mgr = b.empno;
# 子查询
select语句中嵌套select语句,被嵌套的select语句称为子查询。
where子句中的子查询
查询比最低工资高的员工,显示员工姓名和薪资。
Select ename, sal from emp where sal > (select min(sal) from emp);
from子句中的子查询
注意:from后面的子查询,可以将子查询的查询结果当作一张临时表。
找出每个岗位的平均工资的薪资等级。
Select t.*,s.grade from (select job, avg(sal) as avgsal from emp group by job) t join salgrade s on t.avgsal between s.losal and s.hisal;
# 函数
⭐ rank()
rank() over
作用:查出指定条件后的进行排名,条件相同排名相同,排名间断不连续。
说明:例如学生排名,使用这个函数,成绩相同的两名是并列,下一位同学空出所占的名次。即:1 1 3 4 5 5 7
dense_rank() over
作用:查出指定条件后的进行排名,条件相同排名相同,排名间断不连续。
说明:和rank() over 的作用相同,区别在于dense_rank() over 排名是密集连续的。例如学生排名,使用这个函数,成绩相同的两名是并列,下一位同学接着下一个名次。即:1 1 2 3 4 5 5 6
使用:dense_rank() over (PARTITION BY xx ORDER BY xx [DESC])
- row_number() over
作用:查出指定条件后的进行排名,条件相同排名也不相同,排名间断不连续。
说明:这个函数不需要考虑是否并列,即使根据条件查询出来的数值相同也会进行连续排序。即:1 2 3 4 5
使用:row_number() over (over (PARTITION BY xx ORDER BY xx [DESC]))