 如何设计一个高并发架构
如何设计一个高并发架构
# 如何设计一个高并发架构
# 高并发的根源
数据库请求达到每秒两三千的时候基本就要完蛋了,如果数据库瞬间承载5000以上,甚至上万的并发,那一定会宕机,因为 MySQL 根本就抵挡不了高并发。
但现在互联网用的人越来越多,每秒并发量几千、几万、几十万的场景都很正常。那如此高的并发量再加上复杂的业务该如何解决呢?
可以从一下几点解决高并发的问题:
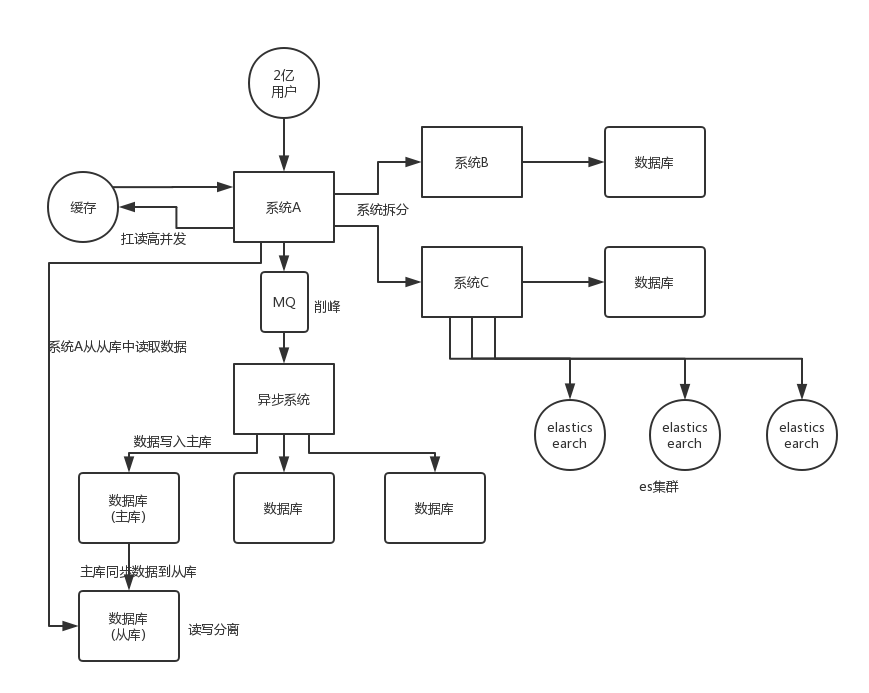
- 系统拆分
- 缓存
- MQ
- 分库分表
- 读写分离
- ElasticSearch
# 系统拆分
将一个系统拆分为多个子系统,用 dubbo 实现远程调用。同时,每个系统连一个数据库,这样数据库的数量从1个变成了多个,就可以抗住高并发了。
# 缓存
Redis 解决的是高并发读的问题,大部分的高并发场景,都是读多写少,所以可以再数据库和缓存里都写一份数据,读的大量请求就可以访问缓存,毕竟 Redis 轻轻松松单机几万的并发量。
# MQ
MQ 解决的是高并发写的问题,因为 Redis 很难担任写的任务,因为数据会过期、数据格式简单、不支持 MySQL 那种复杂的事务,所以写还是要靠 MySQL 自己来完成。但为了不能让大量请求同时访问到 MySQL,所以用 MQ 来实现排队,MySQL 就可以按它自己的能力慢慢写。MQ 单机也能扛得住几万的并发量。
# 分库分表
数据库最后还是难免还是会遇到高并发的问题,那么就可以将一个数据库拆分为多个数据库,多个库就能分担压力;然后将一个表拆分为多个表,每个表的数据量报错少一点,提高 sql 语句的性能。
# 读写分离
读写分离主要也是解决读多写少的情况,没必要将所有的请求都集中当一个数据库上,可以让数据库搞主从架构,主库写入,从库读取,实现读取分离。读流量太多的时候,还可以继续加更多的从库。
# ElasticSearch
ES 是分布式的,可以随便扩容,天然支持高并发。一些简单的查询、统计类的和全文搜索类的操作可以通过 ES 来承载。
编辑 (opens new window)
上次更新: 2023/08/20, 21:21:52