 分库分表
分库分表
# 分库分表
# 为什么要分库分表?
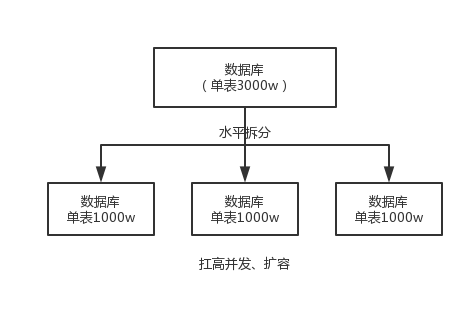
分库分表的原因:数据量太大、并发太大
分表
当单表数据达到几百几千万时,由于单表数据量太大,会极大影响 sql 执行的性能,即使能够运行也会非常慢。一般情况,当单表达到几百万的时候就得分表了。
分表就是把一个表的数据放到多个表中,然后查询的时候就查询对应的表。比如可以按照用户id来分表。
分库
一般而言,一个数据库的并发量达到 2000 就一定要扩容了,而且一个健康的单库并发量最好保持在每秒 1000 左右,不要太大。如果当并发量太大时,就可以拆分成多个库,访问的时候就访问一个库。
| 分库分表前 | 分库分表后 | |
|---|---|---|
| 并发支撑情况 | MySQL 单机部署,扛不住高并发 | MySQL 从单机到多机,能承受的并发增加了多倍 |
| 磁盘使用情况 | MySQL 单机磁盘容量几乎撑满 | 拆分为多个库,数据库服务器磁盘使用率大大降低 |
| SQL 执行性能 | 单表数据量太大,SQL 越跑越慢 | 单表数据量减少,SQL 执行效率明显提升 |
# 如何对数据库如何进行垂直拆分或水平拆分的?
水平拆分:把一个表的数据分到多个库的多个表中,但每个表结构都相同,只不过每个表库放的数据不同,所有库表的数据加起来就是全部数据。水平拆分的意义就是将数据均匀放到更多的库里,然后用多个库来抗住更高的并发,同时也提高了存储容量。
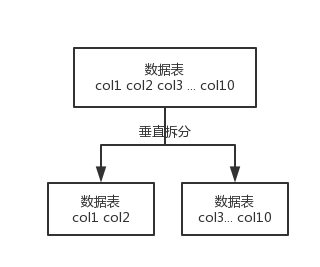
垂直拆分:把一个很多字段的表给拆分成多个表或者多个库,每个表的结构不一样,每个表库都包含部分字段。一般会将较少的访问频率较高的字段放在一个表里,将较多的访问频率较低的字段放到另一个表里。
# 分库分表的方式
range 分,扩容简单,给每个月都准备一个库就可以了,到了一个新的月份就会写到新的库;缺点,大部分数据都是访问最新的数据,实际使用需要看场景。
hash 分,平分配每一个库的数据量和请求压力;缺点时扩容比较麻烦,需要数据迁移,之前的数据需要重新计算 hash 值后重新分配到不同的库或表。
# 分库分表后 id 主键如何处理
🔶 数据库自增 Id
设置数据库 sequence 或者表自增字段步长,每个数据表有一个不同的 起始 ID,有多少个节点,自增步长就是多少。这种方案实现起来比较简单,也能达到性能目标。但是服务节点固定,步长也固定,将来如果还要增加服务节点,就不好搞了。
🔶 UUID
本地生成,不需要基于数据库。缺点,UUID 太长且占空间,作为主键性能太差。更重要的是,UUID 不具备有序性,会导致 B+ 树索引在写的时候有过多的随机写操作。
🔶 雪花算法
snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala 语言实现,是把一个 64 位的 long 型的 id,1 个 bit 是不用的,用其中的 41 bits 作为毫秒数时间戳,用 10 bits 作为工作机器 id,12 bits 作为序列号。
- 1 bit:不用,为啥呢?因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
- 41 bits:表示的是时间戳,单位是毫秒。41 bits 可以表示的数字多达
2^41 - 1,也就是可以标识2^41 - 1个毫秒值,换算成年就是表示 69 年的时间。 - 10 bits:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。但是 10 bits 里 5 个 bits 代表机房 id,5 个 bits 代表机器 id。意思就是最多代表
2^5个机房(32 个机房),每个机房里可以代表2^5个机器(32 台机器)。 - 12 bits:这个是用来记录同一个毫秒内产生的不同 id,12 bits 可以代表的最大正整数是
2^12 - 1 = 4096,也就是说可以用这个 12 bits 代表的数字来区分同一个毫秒内的 4096 个不同的 id。