 IO多路复用
IO多路复用
# IO多路复用
为什么要了解 IO 多路复用技术
- 面试中会考;
- 在 redis、nginx 以及 Java NIO 中都有使用,必要了解一下。
参考视频
IO多路复用底层原理全解 (opens new window):讲的很细致,时间比较长
IO多路复用select/poll/epoll介绍 (opens new window):select 和 poll 讲的很好,epoll 部分就在瞎讲了
# 问题引出
🔊 问题:
如何设计一个高性能的网络服务器,可以供多个客户端同时连接,并且能处理这些客户端传上来的请求?
🙋♂️ 方案1:
使用多线程,每一个线程处理一个请求。但需要 CPU 的上下文切换,当请求特别多的时候效率低。
🙋♂️ 方案2:
使用单线程,在说明解决方法之前我们要知道:
使用单线程时,当一个线程正在处理 A 的请求时,B 发送上来的数据也不会丢失,因为在网卡里有 DMA,它可以在不需要 CPU 的情况下将数据写入到内存当中。
在 Linux 系统中每一个网络连接都是一个文件,在内核中以文件描述符(fd)的形式存在。
我们可以采用下面的方案,把所有文件描述符放到一个数组中进行遍历,如果遍历到某一个文件描述符可以读取数据,那么就执行读取数据的操作。
while(1) {
for (Fdx in [FdA, FdB, ..., Fdn, ...]) {
if (Fdx 有数据) {
读取Fdx数据;
处理数据;
}
}
}
2
3
4
5
6
7
8
虽然可以解决问题,但是它的性能依然不够好,因为它是用我们的程序判断的,并不是从操作系统底层解决的问题。
# select
# select 的作用
在 Linux 中,我们可以使用 select 函数实现 I/O 端口的复用,传递给 select 函数的参数会告诉内核:
- 我们所关心的文件描述符
- 对每个描述符,我们所关心的状态。
- 我们要等待多长时间。
从select函数返回后,内核告诉我们以下信息:
- 对我们的要求已经做好准备的描述符的个数
- 对于三种条件哪些描述符已经做好准备(读,写,异常)
有了这些返回信息,我们可以调用合适的 I/O 函数(通常是 read 或 write),并且这些函数不会再阻塞。
# select API 说明
函数接口:
#include <sys/select.h>
int select(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, struct timeval *timeout);
2
⭐ 返回值
做好准备的文件描述符的个数,超时为 0,错误为 -1
⭐ maxfdp1
整型数,指数组中所有文件描述符的范围,最大的文件描述符的值加 1
⭐ set
中间三个参数指向描述符集,指明了我们关心哪些描述符,并需要满足哪些条件(可写,可读,异常),我们只需理解 readset,只考虑哪些文件描述符已经做好被读的准备了
⭐ timeout
它指明我们要等待的时间:
struct timeval {
long tv_ sec; /*秒 */
long tv_ usec; /*微秒*/
}
2
3
4
有三种情况:
timeout == NULL等待无限长的时间。timeout->tv_ sec == 0 && timeout->tv _usec == 0不等待,直接返回。(非阻塞)timeout->tv sec !=0 || timeout->tv_ usec!= 0等待指定的时间。
# 操作 Fds API
/* 将fd_set的所有位都设为0 */
int FD_ZERO(fd_set *fdset);
/* 清除某个位 */
int FD_CLR(int fd, fd_set *fdset);
/* 将指定位置的bit值设置为1 */
int FD_SET(int fd, fd_set *fdset);
/* 测试某个位是否被置位 */
int FD_ISSET(int fd, fd_set *fdset);
2
3
4
5
6
7
8
9
10
11
# 举例说明
我们以下面这段代码为案例来详细了解 select,我们将逐步分析每一部分
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&addr, 0, sizeof (addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd,(struct sockaddr*)&addr ,sizeof(addr));
listen (sockfd, 5);
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
fds[i] = accept(sockfd,(struct sockaddr*)&client, &addrlen);
if(fds[i] > max)
max = fds[i];
}
while(1){
FD_ZERO(&rset);
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset);
}
puts("round again");
select(max+1, &rset, NULL, NULL, NULL);
for(i=0;i<5;i++) {
if (FD_ISSET(fds[i], &rset)){
memset(buffer,0,MAXBUF);
read(fds[i], buffer, MAXBUF);
puts(buffer);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
⭐ 第一部分:准备文件描述符数组 fds
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&addr, 0, sizeof (addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd,(struct sockaddr*)&addr ,sizeof(addr));
listen (sockfd, 5);
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
// 文件描述符存储到 fds 中,每个文件描述就是一个随机的数字(编号)
fds[i] = accept(sockfd,(struct sockaddr*)&client, &addrlen);
// 求出最大的文件描述符编号
if(fds[i] > max)
max = fds[i];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这部分代码只需要浅浅的了解一下就好了,我们只要知道这几点即可:
- fds 是用于存储文件描述符的数组
- 每一个文件描述符是一个随机的数字(编号)
- max 记录了这些文件描述符中编号最大的值
因为一共建立了 5 个 socket 连接,所以数组的大小为 5。我们可以假设这 5 个文件描述符的编号为1、2、5、7、9

⭐ 第二部分:调用 select 方法
下面代码中使用的 API 在前面都已经介绍了,看不懂的 API 可以再去前面看看
while(1){
// 这里的 rset 集合会反复使用,每次使用之前要全部置 0
FD_ZERO(&rset);
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset);
}
...
}
2
3
4
5
6
7
8
rset 就是即将传入 select 方法中的 readset,它的数据结构是 bitmap,默认大小为 1024。因为它会在每一次循环中反复使用,所以在每一次使用之前都会调用 FD_ZERO() 方法将 rset 位图中的所有位都清零,这个 API 在前面介绍过。
通过一个 for 循环,我们将 fds 数组转换成我们需要的 rset 位图,位图的第 1、2、5、7、9 位置1:
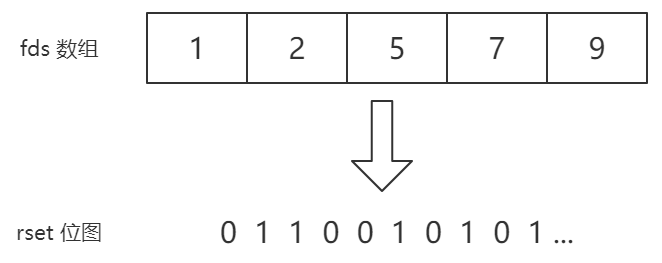
下面开始调用 select() 方法
while(1){
// 这里的 rset 集合会反复使用,每次使用之前要全部置 0
FD_ZERO(&rset);
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset);
}
puts("round again");
// 调用 select 方法,这里我们只关心读,而不关注写和异常,所以只是传入了 readset 的值
// 判断哪些文件已经做好读的准备了
// 超时时间设置为 null,等待无限长时间
select(max+1, &rset, NULL, NULL, NULL); // 没有数据准备好,将一直阻塞在这里
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
前面我们介绍了 select() 方法的 API,这里我们只关心读,而不关心写和异常,所以只传入了 readset 位图,用于判断哪些文件做好了读的准备;超时时间为 null,等待无限长时间。
select 的执行流程如下,先把用户态的 rset 复制到内核态中,在内核态中判断文件描述符是否读取好数据。内核态的判断比用户态效率高,因为用户态的判断也是要通过内核态。如果没有数据准备好,内核态将一直判断,select 函数将一直阻塞在那里。
由于 rset 的位数为 1024,我们只用了其中的 0 到 9 位,遍历剩下的 1000 多位都是浪费,我们可以通过 max + 1 指明我们只需要遍历到 max + 1 位即可,后面的数据不需进行遍历。
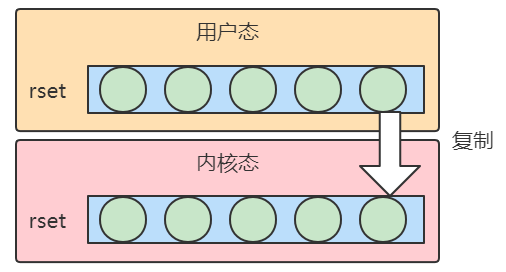
当有数据到来时,内核会将有数据的 fd 置位,表示已经有数据来了(rset 中已经置 1 了,这个地方怎么实现的置位,我不太请),之后 select 将返回,程序将继续向下运行。
while(1){
// 这里的 rset 集合会反复使用,每次使用之前要全部置 0
FD_ZERO(&rset);
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset);
}
puts("round again");
// 调用 select 方法,这里我们只关心读,而不关注写和异常,所以只是传入了 readset 的值
// 判断哪些文件已经做好读的准备了
// 超时时间设置为 null,等待无限长时间
select(max+1, &rset, NULL, NULL, NULL); // 没有数据准备好,将一直阻塞在这里
for(i=0;i<5;i++) {
// 遍历 fds,根据 rset 判断哪些数据可以读取了
if (FD_ISSET(fds[i], &rset)){
// 下面处理数据
memset(buffer,0,MAXBUF);
read(fds[i], buffer, MAXBUF);
puts(buffer);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
遍历 fds,根据 rset 判断哪些数据可以读取了,然后对这些数据进行读取和处理。
# select 总结
我们将全部的文件描述符收集过来交给内核去处理,内核帮我们遍历哪些数据已经准备好了,当其中一个或多个数据准备好后,select 函数会返回,并且有数据的 fd 会置位。返回之后,我们开始遍历数据,根据 rset 来判断哪些数据已经准备好了,并且对准备好的数据进行读取和处理。
提高效率的原因是:将 fd 交给内核去处理,内核处理好后再告诉用户来读取和处理。
select 的缺点:
- rset 位图的默认大小为 1024,处理的数量有上限
- rset 不可重用,每一次使用都需要清零,再通过 fds 数组进行置位
- rset 从用户态拷贝到内核态需要开销
- select 返会后我们知道其中已经有 fd 处于有数据的状态,但是我们不知道哪个或哪几个有数据,我们还需要去遍历所有 fd,时间复杂度为 O(n)
# poll
下面简单介绍以下 poll,了解了 select 的原理,理解 poll 就会很轻松了。
poll 不再使用 bitmap 数据结构,而是定义了一个 pollfd 结构体,poll 的所有改进都是基于整个结构体展开的,所有的文件描述符放在 pollfds 数组中。
struct pollfd {
int fd;
short events;
short revents;
}
2
3
4
5
三个变量的含义:
- fd:文件描述符的编号
- events:在意的事件,读、写或是异常,这里我们只考虑读事件,设置该值为常量 POLLIN
- revents:对 events 的回馈,初始值为 0
# 举例说明
⭐ 我们以下面这段代码为案例来了解 poll,我们将逐步分析每一部分
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
pollfds[i].fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
pollfds[i].events = POLLIN;
}
sleep(1);
while(1){
puts("round again");
poll(pollfds, 5, 50000);
for(i=0;i<5;i++) {
if (pollfds[i].revents & POLLIN){
pollfds[i].revents = 0;
memset(buffer,0,MAXBUF);
read(pollfds[i].fd, buffer, MAXBUF);
puts(buffer);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
⭐ 第一部分:构造 pollfds 数组
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
pollfds[i].fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
// 设置关注的事件为读事件
pollfds[i].events = POLLIN;
}
2
3
4
5
6
7
8
这里假设有 5 个 socket 连接,就是 5 个文件描述符。并将所有的文件描述符放进 pollfds 数组中,并设置关注的事件为读事件。
⭐ 第二部分:调用 poll 方法
while(1){
puts("round again");
// 与 select 一样,poll也是阻塞函数
poll(pollfds, 5, 50000);
for(i=0;i<5;i++) {
// 判断 revents 是否被置位
if (pollfds[i].revents & POLLIN){
// revents 清零
pollfds[i].revents = 0;
memset(buffer,0,MAXBUF);
read(pollfds[i].fd, buffer, MAXBUF);
puts(buffer);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
与 select 一样,poll 也是阻塞函数,当有一个或多个文件准备好后会将 pollfd 结构体中的 revents 置位(revent字段从 0 变为 1)并返回。
通过 for 循环遍历,判断 pollfds[i] 中的 revents 是否被置位,如果置位的话就读取数据并处理。同时,还需要将 revents 恢复为 0, 这样就不需要在每次循环开始的时候对 pollfds 数组进行重新赋值。在 select 中,每次循环开始都需要对 rset 位图进行重新赋值。
# poll 总结
poll 是对 select 的改进,解决了 select 的部分缺点
- 使用 select,rset 位图默认为 1024 位;使用 poll,定义的 pollfds 数组的大小可以设置非常大 (√)
- 使用 select,rset 位图每次循环都要重新赋值;使用 poll,定义的 pollfds 数组可以持续使用,对于处理好的数据只需要令 revents 为 0 即可 (√)
- 使用 select,rset 从用户态拷贝到内核态需要开销;使用 poll,也需要拷贝 pollfds 数组 (×)
- 使用 select,返回后我们还需要去遍历所有 fd 去判断哪个数据准备好了;使用 poll,同样需要判断 pollfds 数组 (×)
# epoll
epoll 是在 2.6 内核中提出的,是之前的 select 和 poll 的增强版本。相对于 select 和 poll 来说, epoll 更加灵活, 没有描述符限制。epoll 使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的 copy 只需一次。
epoll 操作过程需要三个接口,分别如下:
#include <sys/epol.h>
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
2
3
4
# epoll API 说明
⭐ epoll_create
int epoll_create(int size);
epoll_create 函数是一个系统函数, 函数将在内核空间内开辟一块新的空间,可以理解为 epoll 结构空间, 返回值为 epoll 的文件描述符编号,方便后续操作使用。该空间使用的是红黑树,epfd 是红黑树的根节点。
⭐ epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll_ctl 是 epoll 的事件注册函数,epoll 与 select 不同, select 函数是调用时指定需要监听的描述符和事件,epoll 先将用户感兴趣的描述符事件注册到 epoll 空间内,此函数是非阻塞函数,作用仅仅是增删改 epoll 空间内的描述符信息。
epfd:epoll 结构的进程 fd 编号,函数将依靠该编号找到对应的 epoll 结构。
op:表示当前请求类型(增、删、改),由三个宏定义
- EPOLL_CTL_ADD:注册新的 fd 到 epfd 中
- EPOLL_CTL_MOD:修改已经注册的 fd 的监听事件
- EPOLL_CTL_DEL:从 epfd 中删除一个 fd
fd:需要监听的文件描述符。一般指 socket fd
event:告诉内核对该fd资源感兴趣的事件。
struct epoll event { uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ }1
2
3
4events 可以是以下几个宏的集合:
EPOLLIN、EPOLLOUT、 EPOLLPRI、 EPOLLERR、 EPOLLHUP (挂断)、EPOLLET (边缘触发)、EPOLLONESHOT (只监听一次,事件触发后自动从 epoll 列表中清除该 fd)
⭐ epoll_wait
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll_wait 等待事件的产生,类似于 select 调用。根据参数 timeout 来决定是否阻塞
- epfd:指定感兴趣的 epoll 事件列表
- events:是一个指针,必须指向一个 epoll_event 结构数组,当函数返回时,内核会把就绪状态的数据拷贝到该数组中
- maxevents:表明参数二 epoll_event 数组最多能接收的数据量,即本次操作最多能获取多少就绪数据
- timeout:单位为毫秒。
- 0:非阻塞调用,表示立即返回
- -1:阻塞调用,直到有用户感兴趣的事件就绪为止
- 其他:阻塞调用,阻塞指定时间内如果有事件就绪则提前返回,否则等待指定时间后返回
- 返回值:本次就绪的 fd 个数
⭐ 工作模式
epoll 对文件描述符的操作有两种模式:LT(水平触发)和 ET(边缘触发)。LT 模式是默认模式,LT 模式与 ET 模式的区别如下
- LT(水平触发):事件就绪后,用户可以选择处理或者不处理,如果用户本次未处理,那么下次调用 epoll wait 时仍然会将未处理的事件打包给你。
- ET(边缘触发):事件就绪后,用户必须处理,因为内核不给你兜底了,内核把就绪的事件打包给你后,就把对应的就绪事件清理掉了。
ET 模式在很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。
# 举例说明
以下面这段代码为案例来了解 epoll,这里假设有 5 个 socket 连接
struct epoll_event events[5]; // epoll 准备好的数据将放在这里
int epfd = epoll_create(10); // 内存中开辟一块区域,监听列表
...
...
for (i=0;i<5;i++)
{
static struct epoll_event ev;
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
ev.data.fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
ev.events = EPOLLIN; // 触发方式:读触发
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev);
}
while(1){
puts("round again");
nfds = epoll_wait(epfd, events, 5, 10000);
for(i=0;i<nfds;i++) {
memset(buffer,0,MAXBUF);
read(events[i].data.fd, buffer, MAXBUF);
puts(buffer);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
⭐ 第一部分:创建 events 数组
struct epoll_event events[5];
int epfd = epoll_create(10);
2
epoll_create() 函数在前面介绍过,在内核空间内开辟一块新的空间,我们暂且称其为监听列表。该空间结构为红黑树,epfd 是红黑树的根节点,此时 size 为 10,可以存储 10 个 fd。
⭐ 第二部分:添加事件到 events 数组
for (i=0;i<5;i++)
{
// 事件以 epoll_event 结构体的形式存在
static struct epoll_event ev;
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
ev.data.fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
// 指明事件触发方式,读触发
ev.events = EPOLLIN;
// 添加 fd 到 events 中
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev);
}
2
3
4
5
6
7
8
9
10
11
12
将 5 个 epoll_event 结构体添加到监听列表中,epoll_event 跟之前介绍的 pollfd 很像。
⭐ 第三部分:执行 epoll
while(1){
puts("round again");
nfds = epoll_wait(epfd, events, 5, 10000);
for(i=0;i<nfds;i++) {
memset(buffer,0,MAXBUF);
read(events[i].data.fd, buffer, MAXBUF);
puts(buffer);
}
}
2
3
4
5
6
7
8
9
10
epoll_wait(epfd, events, 5, 10000):传入监听列表阻塞等待数据是否准备完毕
当一个或多个数据准备完毕后,准备好的数据就会放到一个 events 数组中,并返回 ndfs 也就是准备好的文件个数。之后根据 ndfs 决定遍历的次数,读取数据并处理。
# epoll 总结
我们将全部的文件描述符收集过来放到 nfds 指向的内核的一块区域,内核帮我们遍历哪些数据已经准备好了,当其中一个或多个数据准备好后,会拷贝到 events 数组当中,epoll 函数会返回就绪的个数,根据就绪的文件个数遍历 events 数组,对准备好的数据进行读取和处理。
与 select 对比
- select,rset 位图的默认大小为 1024;epoll,epoll_create() 函数开辟的内存区域可以很大。
- select,rset 位图不可重用;epoll,nfds 指向的内存区域可以反复使用
- select,rset 从用户态拷贝到内核态需要开销;epoll,这个地方也是有优化,但是我也没有理解明白。
- select ,我们需要遍历 fds 来判断哪些数据已经准备好;epoll,直接处理 events 数组,里面都是准备好的数据。