 Map常见知识点
Map常见知识点
# Map常见知识点
Java 容器的常见 Map 如下:
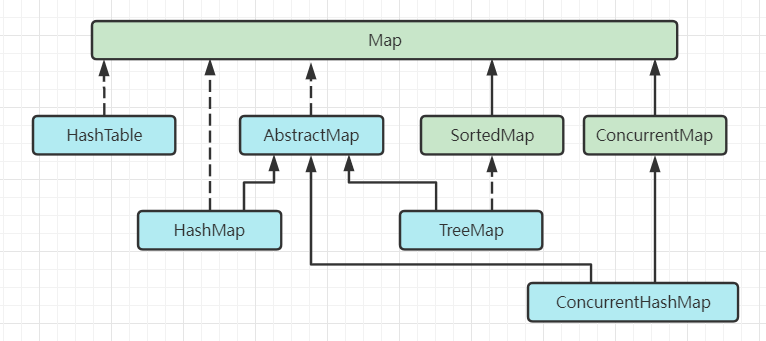
# HashMap 和 HashTable 的区别
HashTable 已被淘汰,并发情况下使用 ConcurrentHashMap
- 线程安全:HashMap 非线程安全;HashTable 线程安全,因为 HashTable 内部的方法基本都有 synchronized 修饰;
- 效率:HashMap 的效率高于 HashTable 的效率;
- 对 null 的支持: HashMap 的 key 和 value 都支持 null,HashTable 不支持 null;
- 初始容量和扩容:HashMap 初始容量 16,每次扩容为原容量的 2 倍;HashTable 初始容量为11,每次扩容为原来的 2n + 1;
- 底层数据结构:HashMap 为数组、链表和红黑树。
# HashMap 和 HashSet 的区别
HashSet 底层就是基于 HashMap 实现的。
HashMap | HashSet |
|---|---|
实现了 Map 接口 | 实现 Set 接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向 map 中添加元素 | 调用 add()方法向 Set 中添加元素 |
HashMap 使用键(Key)计算 hashcode | HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性 |
# HashMap 和 TreeMap 的区别
TreeMap 和HashMap 都继承自AbstractMap ,但是需要注意的是TreeMap它还实现了NavigableMap接口和SortedMap 接口。
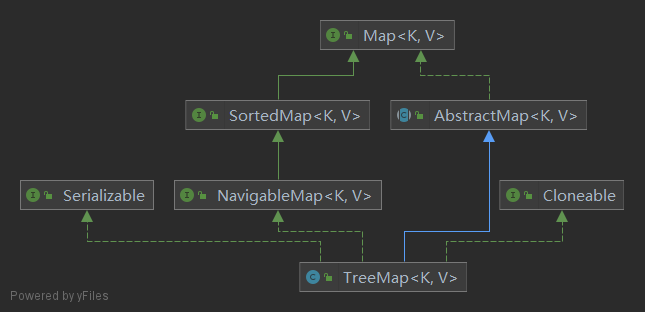
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
实现 SortedMap 接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。
# HashMap 原理
# HashMap 的扰动函数 hash()
hashCode():Object 类的本地方法,通过该方法可以获取对象的哈希值,它将对象在内存中的地址转换为整型数值。任何类都可以重写该方法。
hash():HashMap 类的方法,可以理解为对 hashCode() 的进一步处理,防止一些实现比较差的 hashCode() 方法,通过它可以使散列表分布的更加均匀,以减少碰撞。下面是该方法的源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2
3
4
将高 16 位的哈希值与低16位的哈希值异或,此时高16位不变,低16位会发生改变。
# HashMap 位置计算公式
公式: (length - 1) & hash
由于 length 不会很长,这样就会导致高位的哈希值用不上,不同的哈希值在 HashMap 中可能会得到相同的位置索引,而使用了扰动函数 hash(),就可以把高位的哈希值融入到低位当中,即使 length 数值很小,也可以使用上高位的哈希值。
在使用 HashMap 的 get() 方法时,会通过 tab[(n - 1) & hash]) 获取元素的索引。
# HashMap 的 size 为 2 的冥次方的原因
- 最简单位置计算公式为
hash % length,当 size 为 2 的幂次方时,该方式可以被优化。 - HashMap 中的位置计算公式为
hash(key) & (len-1),此时当 (len-1) 为 1111,即 len 为 2 的幂次方大小时分布之最均匀,故采用两倍扩容的方式。 - 当 length 总是 2 的 n 次方时,
hash % length等价于hash & (length-1),但是 & 比 % 具有更高的效率。
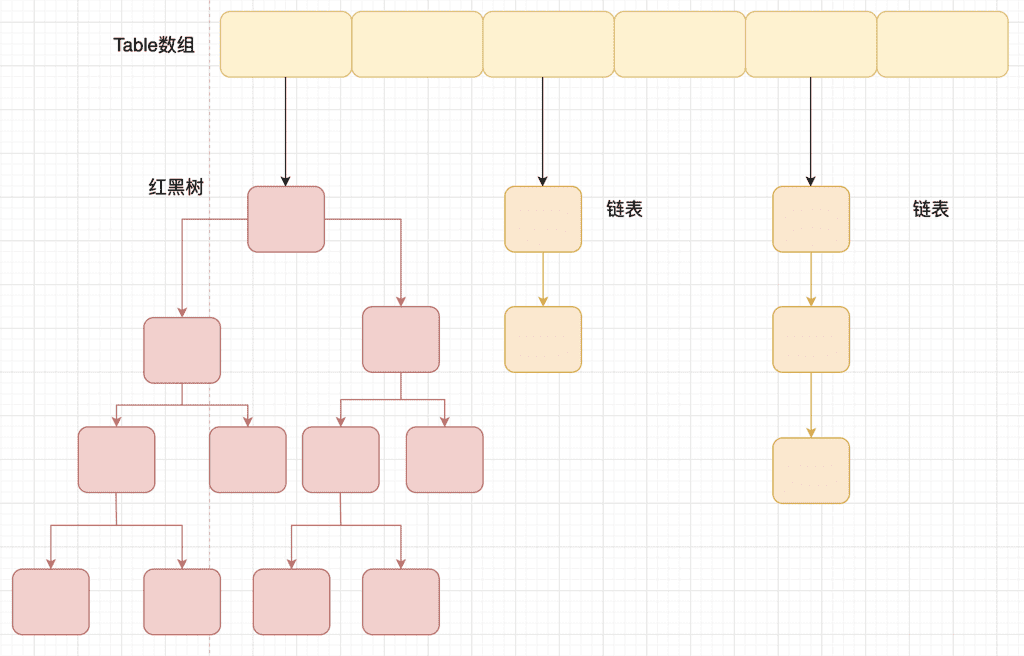
# HashMap 的底层实现原理
底层数据结构为:Entry 数组 + 链表 + 红黑树
通过 (n - 1) & hash 计算位置,如果当前位置不存在元素,则直接放入该元素;当发生哈希冲突时,则采用拉链法解决冲突,新元素插入链表的尾部。
当链表长度大于等于 8,且数组长度大于等于 64 时,将链表修改为红黑树。当链表长度小于6时,红黑树退化为链表.
⭐ loadFactor负载因子,控制数组疏密程度
- 越趋近于1,数组中存放的数据越多,链表越长
- 越趋近于0,数组中存放的数据越少。
loadfactor太大导致查找元素效率低,太小会导致数组利用率低。默认为 0.75
⭐ threshold扩容阈值
threshold = capacity * loadFactor,当 size >= threshold 就对数组进行扩容。
loadFactor 的默认值位 0.75,数组的默认容量位 16,所以当数据量达到 16*0.75=12 时就会扩容
⭐ 为什么不直接使用红黑树完全替代链表呢?
因在HashMap的注释中写道:
* Because TreeNodes are about twice the size of regular nodes,
因为红黑树节点的大小是普通节点大小的两倍,所以为了节省内存空间不会直接使用红黑树,只有达到一定数量才会转成红黑树,这里定义的是8.
⭐ 为什么转换的大小为 8 呢?
和泊松分布有关,在阈值为0.75的情况下,理论冲突节点长度为8的概率为0.00000006,小于千万分之一,是非常小的概率。
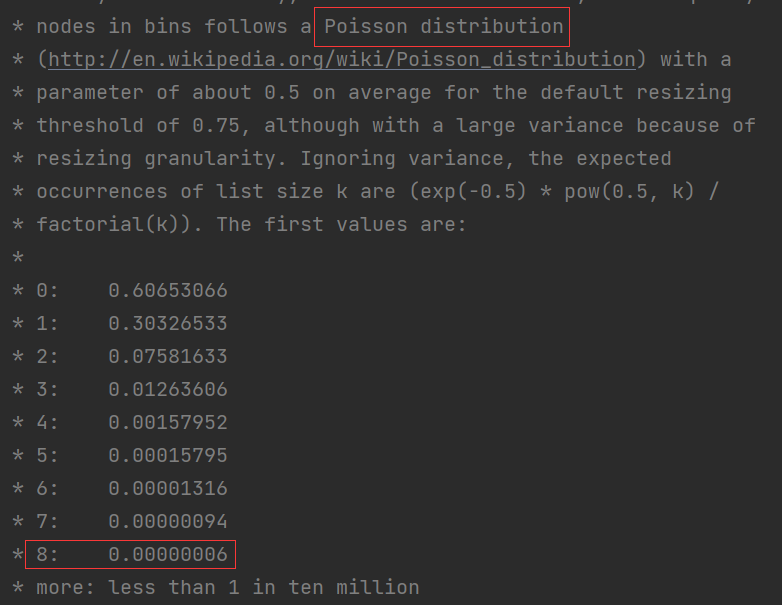
这就是基于时间和空间的平衡,红黑树占用内存大,所以节点少的时候就不用红黑树,如果万一真的冲突很多,就用红黑树,选择参数为8的大小,就是为了平衡时间和空间问题。
泊松分布是一种描述在一段固定时间内,某个事件发生的次数的概率分布。
例如,在一小时内,某个公交车站台上等待的人数、某个网站每分钟收到的访问量、某个工厂每天生产的次品数量等。
泊松分布的特点是:
- 事件发生的次数是离散的,且事件之间是独立的;
- 事件发生的概率在不同的时间段内是相等的;
- 事件发生的平均次数是已知的,且不随时间变化。
泊松分布的概率质量函数为: P(X=k) = (λ^k * e^(-λ)) / k!
其中,X表示事件发生的次数,k表示具体的次数,λ表示单位时间内事件发生的平均次数,e为自然对数的底数(约等于2.71828),k!表示k的阶乘。
# HashMap 的 put 和 get 方法
put方法
put 方法中调用 putVal 方法,putVal 并不提供给用户使用。
putVal方法
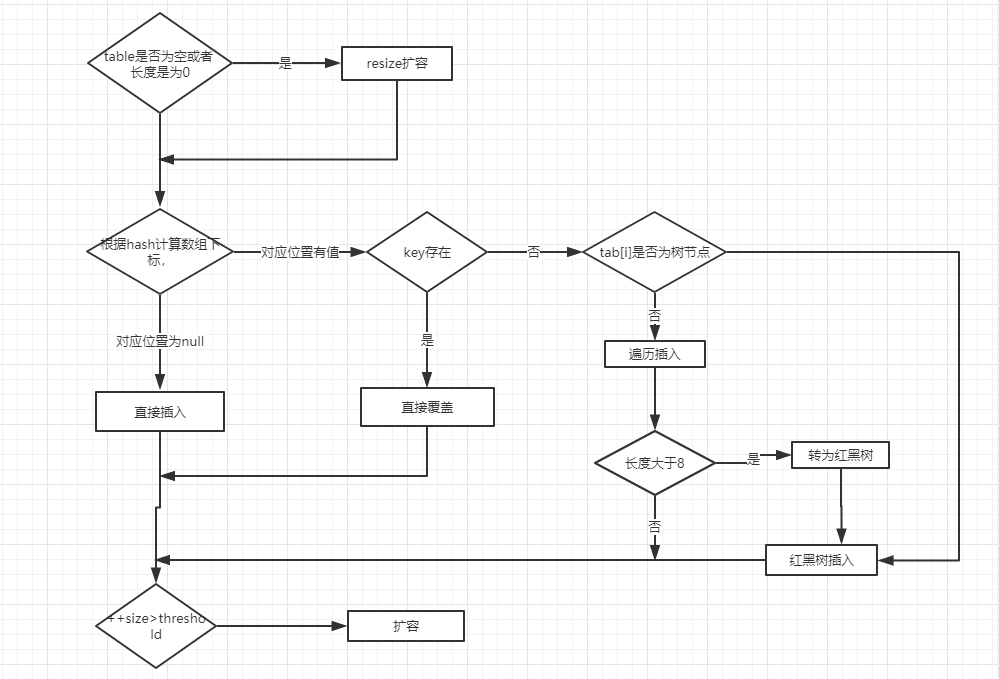
- 判断数组是否为空或者长度为 0,如果是就要 resize 扩容。
- 根据 hash 计算数组下标,如果定位到数组位置没有元素,直接插入。
- 如果定位到数组位置有元素,就要和插入的 key 比较,如果 key 相同就直接覆盖。
- 如果 key 不同,就判断 p 是否是一个树节点,若是树节点,就调用将元素添加进入树节点;如果不是树节点,就遍历链表插入链表尾部。
- 如果链表长度大于 8,且数组长度小于 64,需要对数组进行扩容;如果链表长度大于 8,数组长度大于等于 64,需要将链表转化为红黑树。
- 如果元素个数大于扩容阈值 threshold,需要对数组进行扩容。
get方法
get 方法会调用 getNode 方法。
getNode方法
根据 hash 值和 key 获取节点信息,如果找不到对象则返回 null。
# HashMap 线程不安全的原因
JDK1.7中,当并发执行扩容操作时容易形成环链造成死循环
JDK1.8中,当并发执行put操作时会发送数据覆盖的情况。
https://blog.csdn.net/zzu_seu/article/details/106669757
# HashMap 源码分析
# afterNodeInsertion
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
2
3
4
指的是 LinkedHashMap 中可以被重写以在执行某些操作后执行附加操作的方法。这些方法包括:
- afterNodeAccess方法在访问节点后被调用。例如,更新映射中节点的访问顺序。
- afterNodeInsertion方法在将节点插入映射后被调用。例如,如果映射已超出其容量,则删除最老的节点。
- afterNodeRemoval方法在从映射中删除节点后被调用。例如,更新映射中剩余节点的访问顺序。
# removeEldestEntry
HashMap源码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
...
afterNodeInsertion(evict);
return null;
}
2
3
4
5
LinkedHashMap源码
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
2
3
4
5
6
7
8
9
10
11
LinkedHashMap 中的 removeEldestEntry 方法用于定义在插入新元素后是否删除最老的元素。它允许我们自定义删除最老元素的条件。一般来说,removeEldestEntry 方法的使用场景包括:
- 实现缓存淘汰策略:可以通过重写removeEldestEntry方法来定义缓存淘汰的条件。例如,可以设置缓存的最大容量,当插入新元素后,如果缓存已满,则删除最老的元素。
- 实现LRU(Least Recently Used)缓存:LinkedHashMap本身就是一个按照访问顺序排序的Map,通过重写removeEldestEntry方法,可以实现LRU缓存的自动淘汰。当插入新元素后,如果缓存已满,则删除最老的、最近未被访问的元素。
- 实现定时缓存:可以通过removeEldestEntry方法结合定时任务,定期检查缓存中的元素是否过期,如果过期则删除。
总之,removeEldestEntry方法的使用场景主要涉及需要在插入新元素后自动删除最老元素的情况,可以根据具体需求来自定义删除条件。
# ConcurrentHashMap 原理
# ConcurrentHashMap 结构
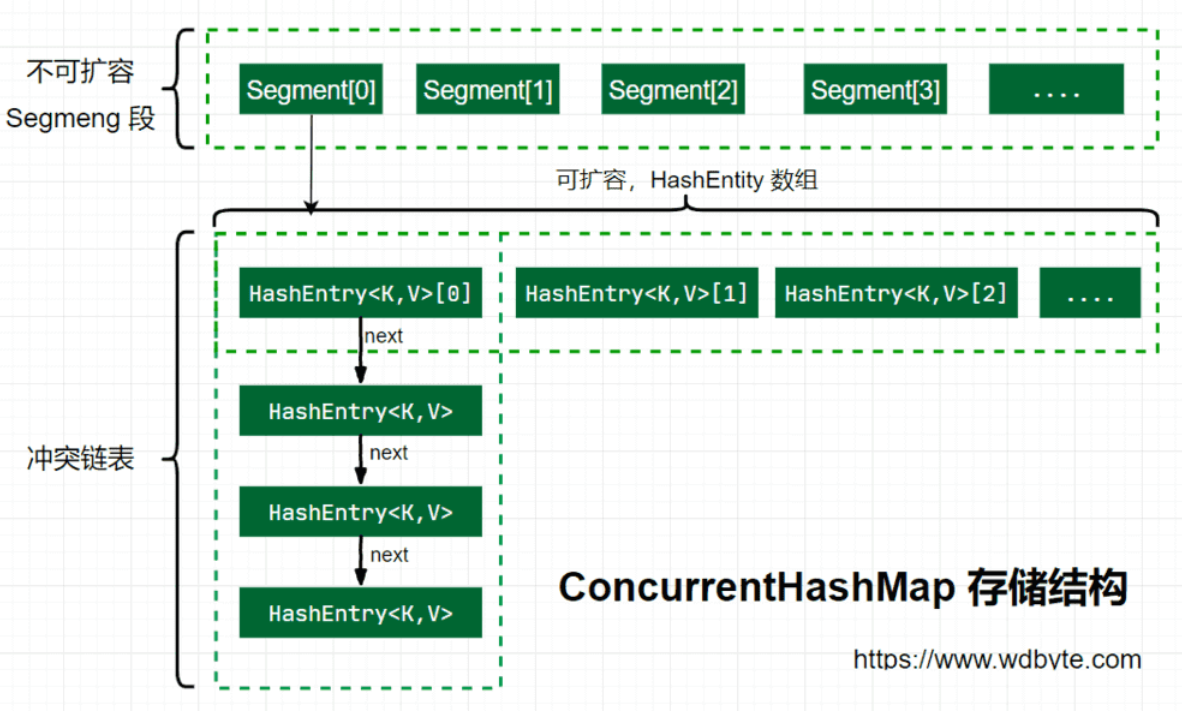
jdk1.7:由多个Segment组成,一个Segment就类似于一个HashMap的结构,每一个Segment可以扩容,但Segment的个数一旦初始化就不能改变,默认Segment时16个,所以可以认为ConcurrentHashMap默认支持16个线程并发。
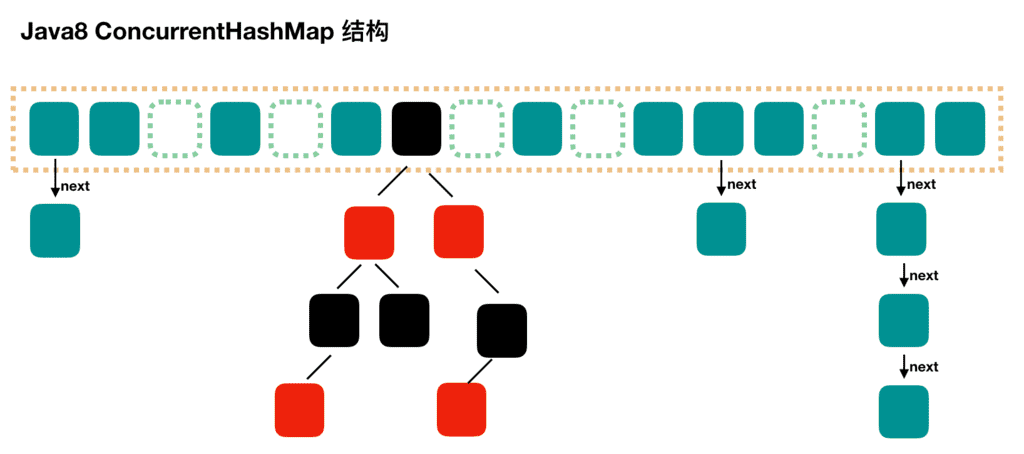
Jdk1.8:使用 Synchronized 锁加 CAS 机制,结构从 Segment 数组 + HashEntry 数组 + 链表进化成了 Node 数组 + 链表/红黑树,Node 是类似于一个 HashEntry的结构,他的冲突达到一定大小时会转化成红黑树,冲突小于一定数量时会退回链表。
# HashMap 和 ConcurrentHashMap 的区别
HashMap:
- JDK1.7之前,基于数组和链表实现的,链表采用头插法。
- JDK1.8之后,在解决Hash冲突的时候有了较大的变化,当链表长度大于阈值(默认为8)时将链表转化为红黑树,以减少搜索时间,链表采用尾插法。将链表转化为红黑树前会判断,如果当前数组长度小于64,那么会选择先扩容,而不是转换为红黑树。
ConcurrentHashMap:
- JDK1.7之前,基于分段数组和链表实现的,使用分段锁segment,每一把锁只锁容器中一部分数据,多线程访问容器里不同数据段的数据就不会存在锁竞争的情况,提高并发访问效率。
- JDK1.8之后,摒弃Segemtn概念,直接使用Node数组+链表/红黑树,并发控制使用synchronized和CAS来操作。synchronized只锁定当前链表或红黑树的首节点。
# ConcurrentHashMap 源码
# 构造器
给定初始容积构造 ConcurrentHashMap(int initialCapacity)
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
2
3
4
5
6
7
8
初始化容积 >= MAXIMUM_CAPACITY的二分之一时,初始体积就设置为MAXIMUM_CAPACITY;
否则,通过tableSizeFor计算初始体积的二分之三(预留一部分空间,防止冲突)。
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
2
3
4
5
6
7
8
9
通过该方法将 c 转换为 2 的倍数。
给定Map构造 ConcurrentHashMap(Map<? extends K, ? extends V> m)
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public void putAll(Map<? extends K, ? extends V> m) {
// 尝试先resize能够容纳所有元素
tryPresize(m.size());
// for循环添加元素
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
putVal(e.getKey(), e.getValue(), false);
}
2
3
4
5
6
7
8
9
10
11
12
# 属性 sizeCtl
sizeCtl 属性在各个阶段的作用
sizeCtl和transferIndex这两个属性来协调多线程之间的并发操作,并且在扩容过程中大部分数据依旧可以做到访问不阻塞.
(1)新建而未初始化时:用于记录初始容量大小
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0) throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
2
3
4
5
6
7
8
9
10
(2)初始化过程中:设置为 -1 表示集合正在初始化中,其他线程发现该值为 -1 时会让出CPU资源以便初始化操作尽快完成
// 代码中共有2处
U.compareAndSwapInt(this, SIZECTL, sc, -1)
2
(3)初始化完成后:用于记录当前集合的负载容量值,也就是触发集合扩容的极限值
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
...
sizeCtl = sc;
2
3
4
5
(4)正在扩容时:用于记录当前扩容的并发线程数情况,此时 sizeCtl 的值为:((rs << RESIZE_STAMP_SHIFT) + 2) + (正在扩容的线程数) ,并且该状态下 sizeCtl < 0
// 第一条扩容线程设置的某个特定基数
U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
// 后续线程加入扩容大军时每次加 1
U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)
// 线程扩容完毕退出扩容操作时每次减 1
U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)
2
3
4
5
6
7
8
下面这些参数在ConcurrentHashMap的扩容机制中起到关键作用。在进行扩容时,可以避免ABA问题,并且可以限制参与扩容的线程数量。
// 用于记录在sizeCtl中的生成戳所使用的位数。生成戳用于标识扩容操作的代数,以避免ABA问题。
private static int RESIZE_STAMP_BITS = 16;
// 用于限制参与扩容操作的最大线程数。
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 用于将生成戳的位移量记录在sizeCtl中
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
2
3
4
5
6
7
8
# 方法 tryPresize()
以下两种情况会调用tryPresize()方法:
- putAll批量插入
- 插入节点后发现链表长度达到8个或以上,但数组长度为64以下时触发的扩容
该方法会根据传入的size参数计算出一个新的容量c。然后,它会进入一个循环,不断尝试调整表格的大小,直到满足以下条件之一:
- 当前的sizeCtl小于0,表示已经有其他线程在进行调整大小操作,此时当前线程会退出循环。
- 当前的容量c小于等于sizeCtl,表示已经有其他线程在进行调整大小操作,并且已经将容量调整到了c或更大,此时当前线程会退出循环。
- 当前的容量n已经达到了最大容量MAXIMUM_CAPACITY,此时当前线程会退出循环。
在循环中,会根据不同的情况进行不同的操作:
- 如果表格为空或长度为0,会尝试将sizeCtl设置为-1,表示当前线程正在进行调整大小操作,并创建一个新的表格。
- 如果当前容量c大于sizeCtl,并且当前表格与原始表格相同,会尝试将表格进行扩容,并更新sizeCtl的值。
- 如果当前sizeCtl小于0,并且满足一些条件,会尝试将sizeCtl的值加1,并进行表格的迁移操作。
private final void tryPresize(int size) {
// 根据size初始化容量
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
// 临时的sizeCtl,扩容阈值
// (1) putAll批量插入时, 为计算好容量
// (2) 扩容时,
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 如果数组初始化则进行初始化,这个选项主要是为批量插入操作方法 putAll 提供的
if (tab == null || (n = tab.length) == 0) {
// 取一个最大值容积
n = (sc > c) ? sc : c;
// CAS设置sizeCtl为-1,表示集合正在初始化中
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
// 初始化完成,将阈值设置为当前容量的3/4。当表格的元素数量达到或超过这个阈值时,就会触发下一次的表格调整操作,即进行扩容操作。
// 这与HashMap的Threshold=0.75一个道理
sc = n - (n >>> 2);
}
} finally {
//初始化完成后 sizeCtl 用于记录当前集合的负载容量值,也就是触发集合扩容的阈值
sizeCtl = sc;
}
}
}
// c小于阈值sc,说明已经完成扩容;当前容量n已经达到了最大容量MAXIMUM_CAPACITY也停止扩容
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
// 插入节点后发现链表长度达到8个或以上,但数组长度为64以下时触发的扩容会进入到下面这个 else if 分支
else if (tab == table) {
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52